Whoops - When Did My Image Links Start Breaking?! - Technical Post-Mortem


Last week, a routine visit to my blog, intended to retrieve information for a work project, unveiled a series of broken image links that sparked a comprehensive review and rectification process. This post-mortem report outlines the discovery, analysis, and resolution of the issue, highlighting the steps taken to prevent future occurrences.
Discovery

The issue came to light when I accessed an article on my blog https://mrstebo.co.uk to gather insights on setting up linting and husky for a project at work. To my surprise, several images within the post were not loading, presenting a clear indication that something was amiss.
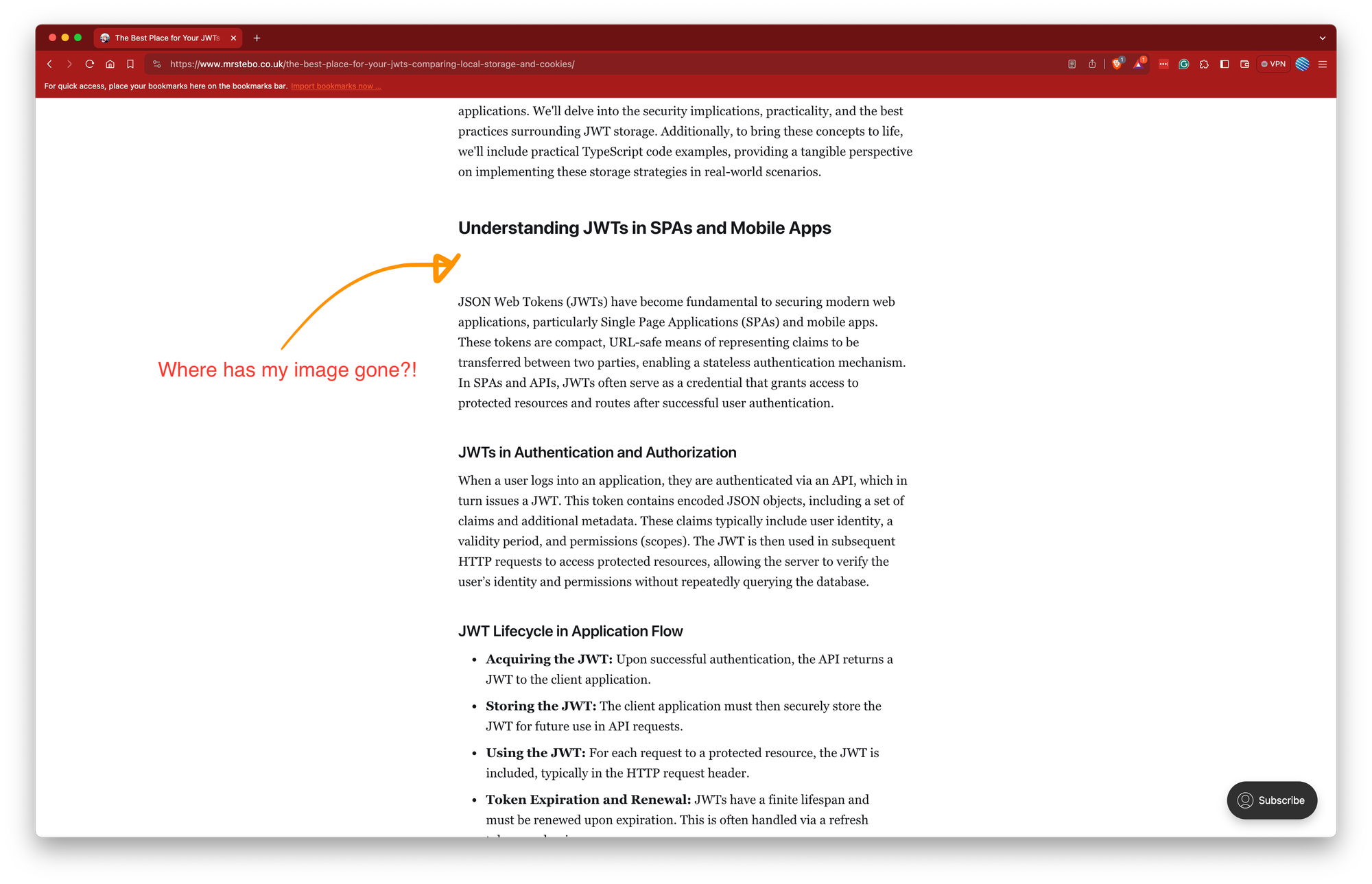
Initial Analysis

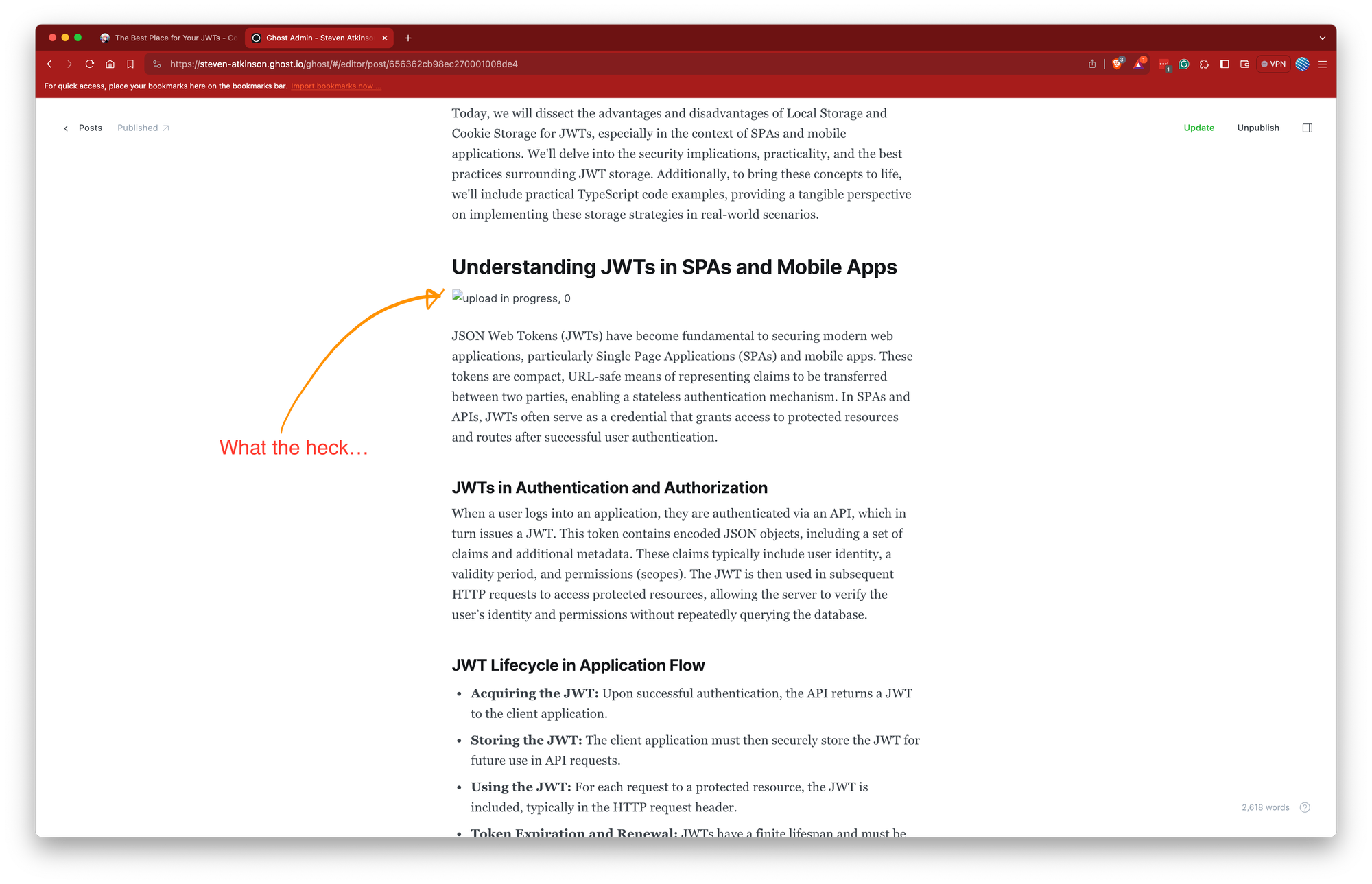
To understand the scope of the problem, I navigated to the Ghost admin area, which serves as the backend for content management on my blog. The images failed to load in the admin area as well, suggesting the issue was not isolated to the frontend.
Utilizing browser developer tools, I conducted a deeper investigation into the source of the images. This revealed that the broken links were attempting to load images from a Discord CDN. This was a critical insight, as it indicated the root cause: images were copied directly from Discord chats instead of being properly downloaded and uploaded to the blog.
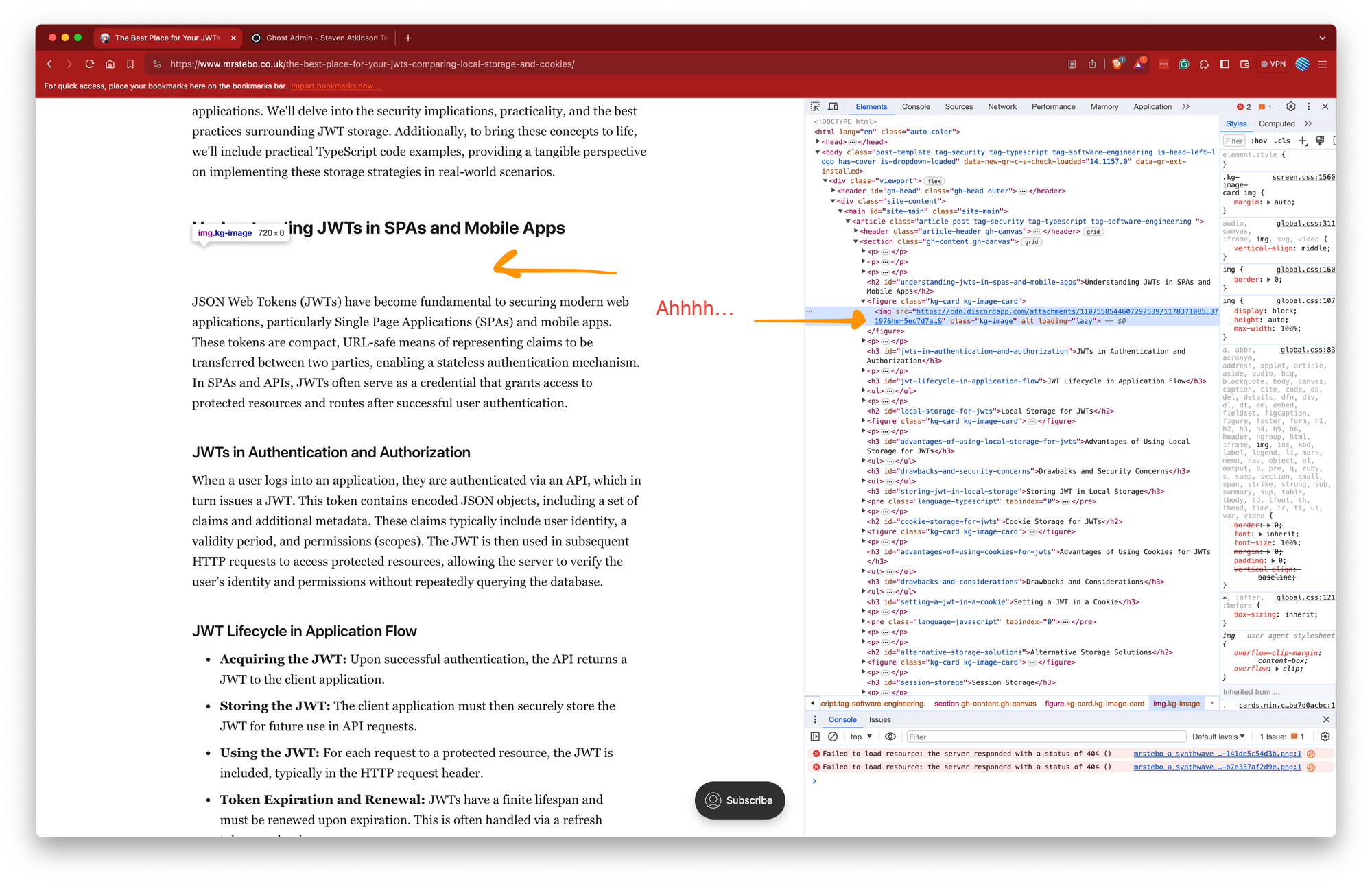
Scope of the Issue

To quantify the extent of the issue, I developed a Ruby script to scan my blog's sitemap for any articles containing Discord CDN links. This script efficiently parsed the sitemap, identifying articles with potentially broken image links.
require 'net/http'
require 'nokogiri'
require 'json'
def get_posts_links_from_sitemap(sitemap_url)
uri = URI(sitemap_url)
response = Net::HTTP.get(uri)
doc = Nokogiri::XML(response)
doc.css('loc').map(&:text)
end
def get_discord_image_links_from_page(page_url)
uri = URI(page_url)
response = Net::HTTP.get(uri)
doc = Nokogiri::XML(response)
doc.xpath('//img[@src]')
.select {|img| img['src'] =~ /discordapp/ }
.map {|img| img['src']}
end
def save_image_list_to_file(image_list, file_path)
File.open(file_path, 'w') do |file|
file.write(image_list)
end
end
post_links = get_posts_links_from_sitemap('https://www.mrstebo.co.uk/sitemap-posts.xml')
image_links = []
post_links.each do |link|
puts "Getting images from #{link}"
images = get_discord_image_links_from_page(link)
puts "Found #{images.count} images"
if images.size > 0
image_links.push({link: link, images: images})
end
end
save_image_list_to_file(JSON.pretty_generate(image_links), 'images.json')A Ruby script that gets posts from the sitemap and checks each post for Discord CDN links
Dependencies
To run this script, the following dependencies were necessary, outlined in a Gemfile:
source 'https://rubygems.org'
gem 'nokogiri'
Outcome
The script output a JSON file listing the affected posts and their respective Discord-hosted image links. Here's a snippet of the output:
[
{
"link": "https://www.mrstebo.co.uk/make-it-dark-putting-the-engine-together/",
"images": [
"https://cdn.discordapp.com/attachments/image_link_1.png",
"https://cdn.discordapp.com/attachments/image_link_2.png"
]
},
{
"link": "https://www.mrstebo.co.uk/make-it-dark-turning-requirements-into-code/",
"images": [
"https://cdn.discordapp.com/attachments/image_link_3.png",
"https://cdn.discordapp.com/attachments/image_link_4.png"
]
}
]
A snippet showing the output of the script
Resolution

Armed with the list of affected articles, I embarked on a task to replace the broken links. This involved locating the original images in Discord, downloading them, and uploading them directly to the respective blog posts. This process not only restored the intended visual content but also ensured the images were now hosted within a more reliable and controlled environment.
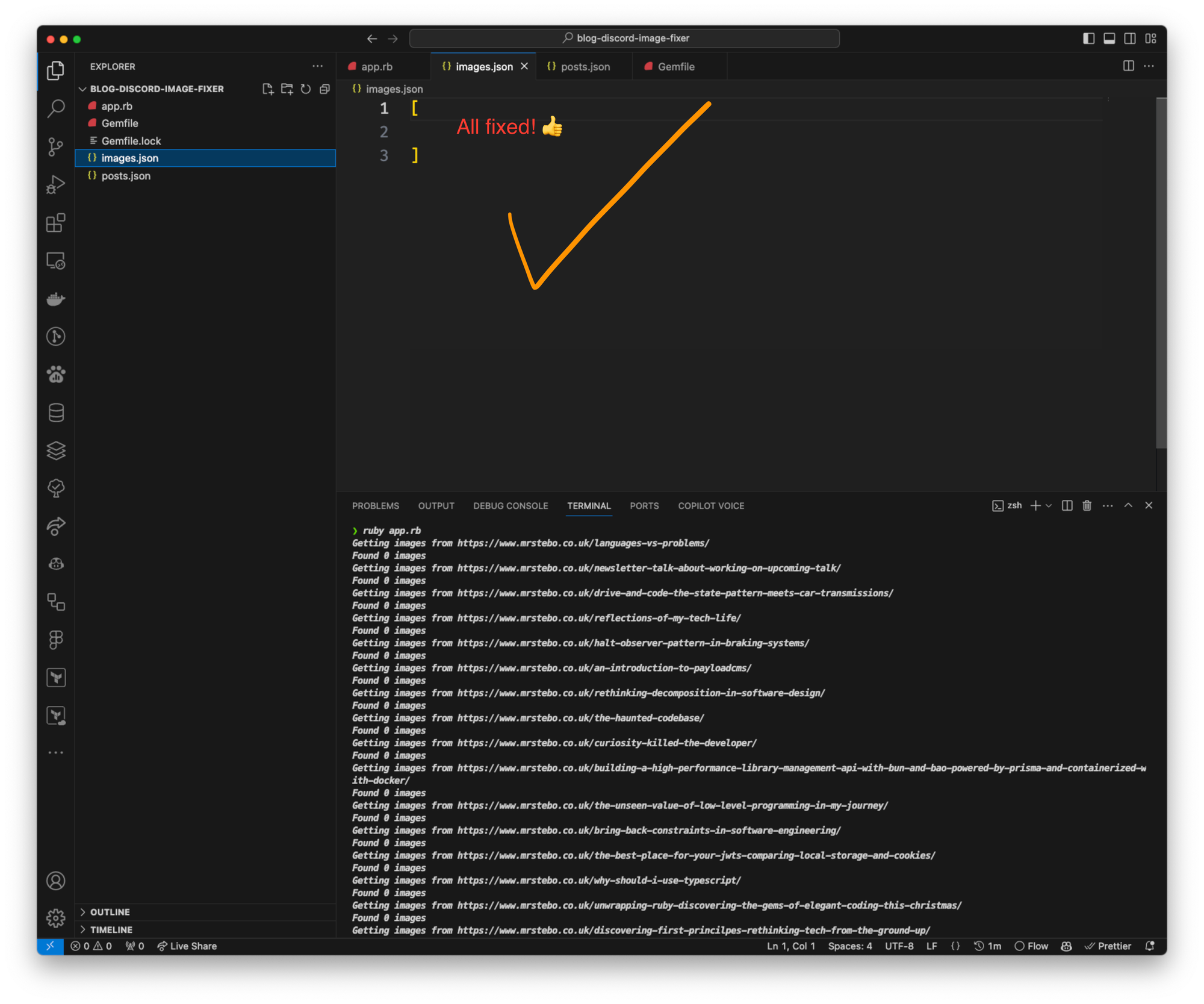
Preventative Measures

To prevent a recurrence of this issue, I am in the process of developing monitoring tools specifically designed to detect broken links on the blog. These tools will extend beyond image links, encompassing all external links to ensure the integrity and reliability of the blog's content.
Conclusion

This incident highlighted the importance of a meticulous approach to content management, especially regarding the sourcing and hosting of images. The resolution has not only corrected the immediate issue but has also spurred the development of tools and practices that will enhance the blog's long-term maintenance and reliability. Through this post-mortem, I have taken a critical step towards ensuring a more robust and resilient digital presence.